本課程會使用到R與Python 語言, 我只會著重在python 語言的範例上
對R有興趣的同學可以到Udemy 上報名這個課程, 看老師講解更多關於R語言的範例
Anaconda 是一個package 的概念, 初學者可以一次下載到python 套件與Editor
因為網路上已經有許多Anaconda 的安裝教學, 這邊我不多加贅述安裝細節
Anaconda 官網 https://www.anaconda.com/products/distribution
我會使用Anaconda 裡的Spyder Editor 來練習課程中講到的範例
數據預處理是機器學習中重要的一環, 之後的小節會著重在下列的細項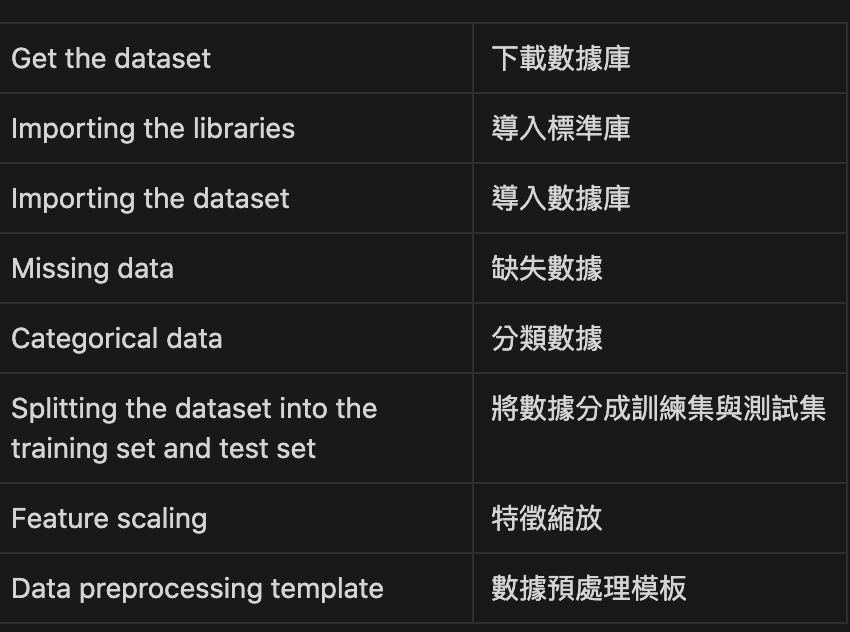
課程中用到的dataset都在這邊, 先下載下來
https://www.superdatascience.com/pages/下载数据集
如圖, Machine Learning A-Z Template Folder 裡面都是空的folders
讓學生可以將課程範例放到對應的section folders 中
Data-Preprocessing.zip 就是本節用到的sample code, 可以解壓縮放到template folder中
Machine Learning A-Z Template Folder 如下
Libraries 相當於是工具包, 裡面提供非常多工具(i.e APIs) 讓使用者使用
如果我們需要用某一種方法來得到目的, 就要用對Libraries
常用Libraries
# number processing
import numpy as np
# drawing
import matplotlib.pyplot as plt
# excel data handling
import pandas as pd
資料通常是以.csv 的方式存在, 那要如何載入資料到程式中呢?
可以用read.csv()來import the data
dataset = read.csv('Data.csv')
編輯完後執行Run之後右下角Console 會顯示Compile 狀態
當build 過之後可以點Variable Explorer 可以看到右上視窗出現dataset 變數的內容
double-click dataset 便會出現完整的資料樣貌, 如圖中間的表格
本範例的資料包含 country, age, salary, purchased
purchased 欄位為應變量(會受到自變量的影響)
其他欄位為自變量
index 代表數據集行數, 可以看到python 是從0開始的, 但R是從1開始
salary是數字, 想要改變表示方法可以選 Format 按鈕來改(ex: %.3g 改成%.0f)
(.3 代表顯示小數點後三位, g 代表科學記號法)
(.0 代表小數點後0位, f 代表float 浮點數)
下圖我已將format 改為float
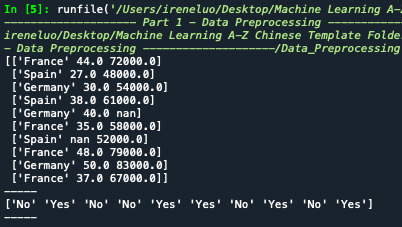
接下來利用iloc(row, column).values 取出datast中的欄位值
x 會取出country, age, salary 欄位
y會取出purchased欄位
印出來如下圖
# arg1=: means all the rows in this dataset
# arg2=:-1 means all the columns except the last one
x = dataset.iloc[:, :-1].values
#args2=3 means column 3
y = dataset.iloc[:, 3].values


 iThome鐵人賽
iThome鐵人賽